Principal Researcher: Hideyuki Tanushi
With the promotion of open science, the development of methods and infrastructure for routine research data management, including acquisition, analysis, sharing, publication, and utilization of research data, has become an urgent issue for academic institutions. One of the research themes of the Research Data Management Team of this laboratory is the research and development of research data infrastructure and research data management technology that contributes to the promotion of the publication and utilization of research data. This team is collaborating with other departments to promote open science by utilizing ONION (Osaka university Next-generation Infrastructure for Open research and open innovatioN), a data aggregation infrastructure that aggregates data generated inside and outside the campus.
The Core Facility Center of our university has developed and distributed a system that enables data sharing within departments via a network by aggregating measurement data from shared analytical apparatus that are isolated from the network onto a NAS (network attached storage) in the analytical laboratory, and then distributing the data through the NAS (see Fig. 1). The system has been distributed to the university-wide analytical laboratories. The NAS of the measurement data aggregation and distribution system is connected to ONION using the S3 (Amazon Simple Storage Service) protocol, enabling the sharing of measurement data among researchers within the campus and contributing to more efficient distribution of research data within the campus.
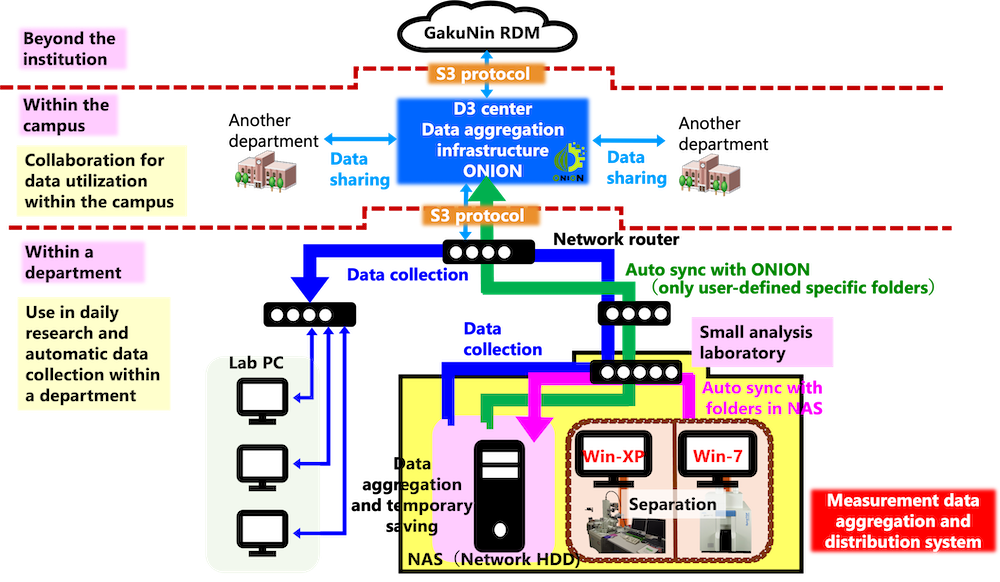
Fig. 1 Collaboration between a measurement data aggregation and distribution system and ONION
However, research data to which metadata has not been assigned has no guarantee of authenticity, and its provenance is unknown. If metadata is inadequate, it will be impossible to promote the utilization of research data, even when research data is aggregated in a data infrastructure. In addition, metadata for research data is diverse unlike that for academic papers. Therefore, we aimed to develop a metadata registration and management system that facilitates the management of research data and reduces the burden on researchers, thereby improving research efficiency, facilitating the assurance of research integrity, and promoting the utilization of research data.
Experimental research data is characterized by the generation of a large amount of failed experimental data in the research process. In Japan, a 10-year retention period guideline has been established for research data as a countermeasure against research misconduct, and all research data, including failed data, should be covered from the perspective of research data management and research integrity assurance. However, researchers currently must manually assign metadata themselves. It is wasteful and a great burden for researchers to manually assign all metadata even for failed data. Therefore, it is important to develop a metadata registration and management system that can manage all research data while reducing the burden on researchers.
Based on the aforementioned considerations for developing the metadata registration and management system, the following requirements were established and the concept was developed (see Fig. 2).
-
- The system must cover all research data, and the data should be controlled and traceable.
→ Data cannot be sent to the NAS unless a unique identifier and metadata are assigned to all measurement results from shared analytical apparatus in the measurement data aggregation and distribution system for small-scale analytical laboratories. - For the benefit of the researcher, the system should contribute to the management, tracking, etc. of research data by the researcher.
- The system should be a metadata collection and aggregation system with an eye to future data utilization (open research data).
→ Collecting and managing metadata separately on a metadata server makes it possible for metadata to be referenced from inside and outside the campus. - The system should never burden the researcher with any additional input or other work.
→ An application that assigns unique identifiers and metadata for apparatus control PCs should be developed, and an interface that allows manual input of essential metadata other than metadata that can be assigned automatically should be provided. - The method of metadata collection and aggregation should be aligned with the way experimental researchers conduct their research.
→ Detailed metadata can be appended and synchronized to the metadata server only when the experimental results are as expected by storing measurement data and their metadata separately on a NAS in the department.
- The system must cover all research data, and the data should be controlled and traceable.
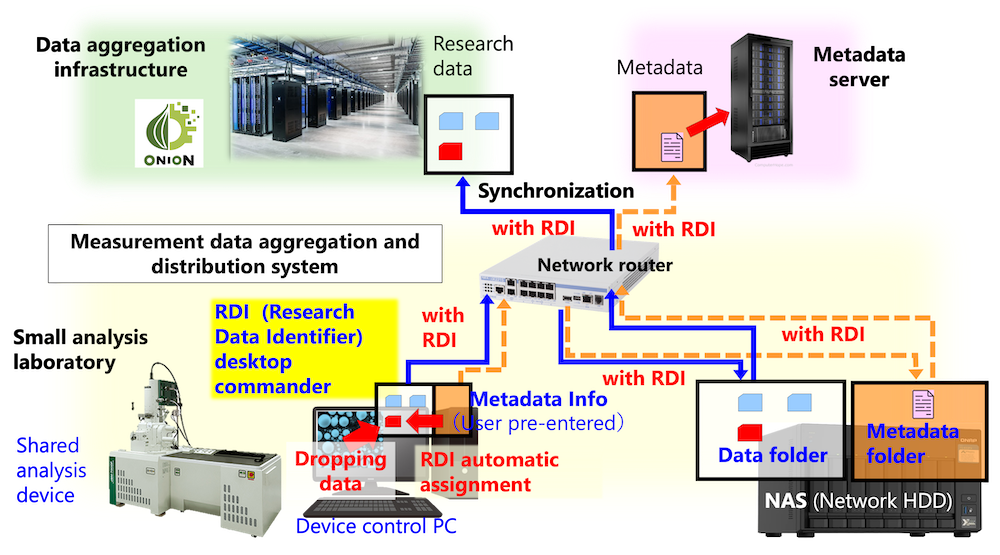
Fig. 2 Conceptual image of the metadata registration and management system in a small-scale analysis laboratory
In the next step, the following research issues will be addressed in order to realize the developed concept as a metadata management system:
- Establishing a method for assigning metadata and unique identifiers to measurement data.
- Constructing a catalog server that handles metadata registration, retrieval, and browsing.
- Establishing a model system to send metadata to the catalog server for registration.
Through the construction of this model system, we aim to enhance the Findability and Accessibility of the FAIR Principles, which are principles for the publication and sharing of research data, and to promote the utilization of measurement data.
[International Conference (w/ review)]
Hideyuki Tanushi, Hiroshi Furutani, Takeo Hosomi, Naoto Kai, Kaname Harumoto and Susumu Date, “Towards Development of University-wide Data Aggregation and Management Infrastructure for Research Data Utilization”, NRDPISI-1, eScience2024, Osaka Japan, Sep. 2024. [DOI: 10.1109/e-Science62913.2024.10678692]